UNMC’s Clinical Research Analytics Environment (CRANE) is a flexible, inclusive clinical data warehouse combined with the tools, processes, and people needed to support knowledge discovery. It contains de-identified, structured data for UNMC research and quality improvement efforts. CRANE can be used as a search discovery tool allowing qualified researchers to search de-identified patient data from sources that would otherwise require IRB-approval or asynchronous consideration. CRANE is considered an environment because it is more than just the software and available data. CRANE is an entire ecosystem consisting of an IRB-approved, de-identified clinical data warehouse (CDW) that provides researchers with access to well organized, characterized, and standardized patient-level data in compliance with HIPAA, the common rule, and best practices. This CDW consolidates data from a variety of clinical sources to present a singular, multi-faceted view of the available data.
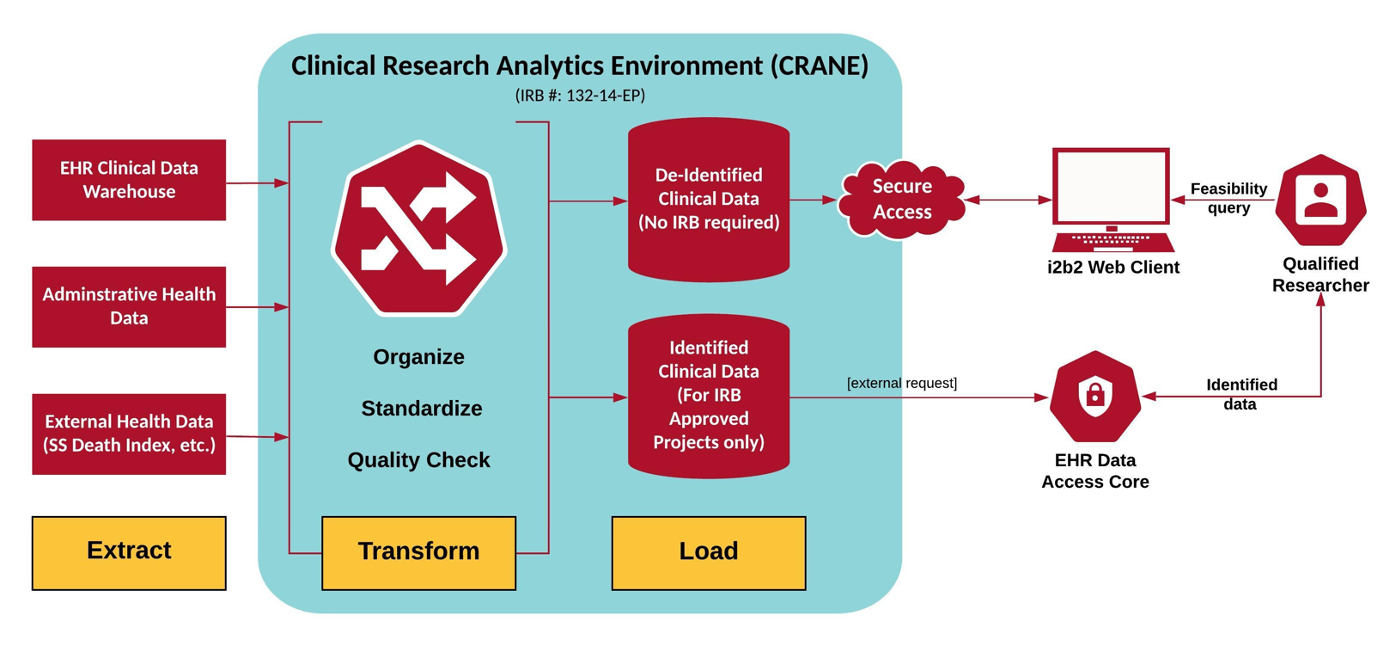
The primary data in CRANE derives from the Nebraska Medicine Electronic Health Record (EHR) system through a series of extracts and transformations to render the data in a well-characterized, interoperable format based on the PCORnet Common Data Model. The EHR data is supplemented with other patient-level data sources including, but not limited to, state cancer registry data, encounter data from the Nebraska Health Information Initiative, and the Social Security death index. Additional data sources to expand the patient-level data include formally encoded anatomic pathology data, biomarker data, and pointers to biobank specimens. This creates a rich repository for health research as it is actually happening in a clinical setting.
The data in CRANE is rendered in the Office of the National Coordinator for Health Information Technology (ONC) approved standard codes and supports external analysis by both R and SAS statistical software. The de-identification process involves comprehensive removal of all 18 PHI identifiers defined by HIPAA as well as a complex date shifting process. Date shifting is inconsistent among patients but is consistent at the individual patient level for each instance of CRANE. This results in dates that are shifted between 1 and 30 days in the past across all of a patient’s data points.
In an effort to support clinical researchers without exposing them to the technical details, CRANE uses an integrated approach providing a “self-serve” data mechanism for qualified researchers. Researchers interact with the data in CRANE primarily through the i2b2 (Informatics for Integrating Biology with the Bedside) web client. I2b2 is a cohort discovery tool developed by Harvard informaticists that allow researchers to determine if there is a cohort of patients in our clinical data repository that meets their criteria of interest using a drag-and-drop interface for ease of use. In summary, CRANE is the entire research environment while i2b2 is the web client portion of that environment through which researchers engage with the underlying data.
To submit a data request click here
A sample of some of the research derived from CRANE is available on our News, Research, and Development Projects page.